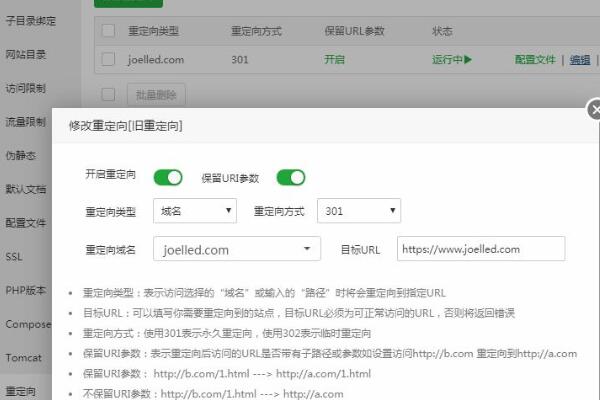
网站日志分析点,Spider IP段详细介绍“技术篇”
一篇值得珍藏的Spider抓取,网站日志分析点,日志中常常看到一堆的IP以及状态码感觉特别懵逼,从中分析Spider的爬行规律,并且投其所好摒弃不足之处,与Spider谈恋爱,只有从细节开始~日志分析就是最好的一个突破点,定期观察能节约不少的优化成本。

日志的分析在SEO工作中是一种重要的内容之一,那么在什么情况下我们需要做日志分析。
网站刚搭建,可以使用日志分析Spider私发来爬行;
网站收录了,不过总的收录量并没有提升需要分析日志看Spider的活跃情况;
网站收录减少,需要分析日志看是否服务器出现问题;
网站首页被K,需要了解日志中Spider爬行首页的情况;
网站全部被K,通过日志我们可以分析Spider最近的动态;
那么在分析日志的时候,一般我们需要看那些地方,分别需要得出什么样的结论,这样的日志数据对接下来的工作是否有意义;
网站日志分析的角度是从Spider角度分析,一般直观得到的数据是Spider访问次数、停留时间、返回码,可以从中计算出Spider的访问次数以及平均抓取量、重复抓取率;我们都知道网站的收录与Spider的赚钱息息相关,抓取的量大说明网站页面受到了Spider的喜欢。
所以抓取量与平均抓取量的提升或下降,从中我们可以看出这个网站的结构情况,Spider的总访问量说明网站的规模;平均停留时间说明Spider爬行一个页面所花费的时间,减少这个时间无疑是对网站有重要意义的,
Spider抓取量的数据,从中分析出网站是否让Spider不断的爬行无效页面,是否浪费很多Spider,从Spider的重复率可也是同理,重复抓取并不能是收录量提升,而收录量与网站的权重排名流量有很大的关系;
Spider抓取间隔时间,在日志中可以看到,会从间隔时间的变化分析出网站在服务器端的问题;
结合网站流量趋势以及Spider的爬行趋势,流量在大幅度减少这样是很不正常的,而在不正常的情况下,同时间段的Spider爬行也会出现异常,可以从返回码是否正价来判断服务器是否稳定;
还有一点就是在搜索引擎在更新算法的时候,Spider就会出现异常,而Spider的总访问量也会不断增加;
以上讲了日志分析的要点,下面就给大家一份曾道听途说的IP段分析,成与不成自己把握,毕竟IP段本身并不好记;
转载自:http://mrdede.com/?p=2289